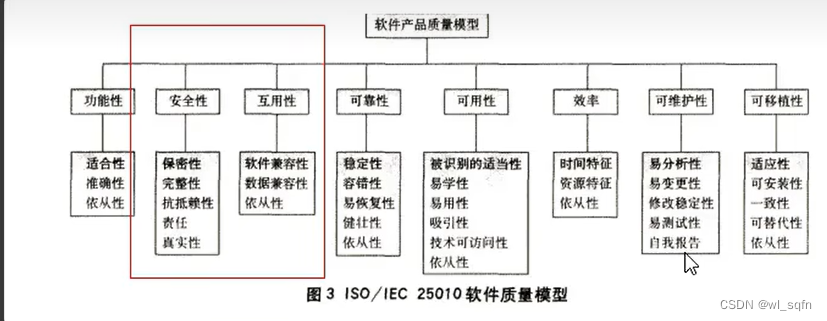
1. 什么是GAUC
GAUC (group auc)实际上是计算每个用户的auc,然后加权平均,最后得到group auc,这样能减少不同用户间的排序结果不好比较这一影响。具体公式为
GAUC
=
∑
(
u
,
p
)
ω
(
u
,
p
)
×
AUC
(
u
,
p
)
∑
(
u
,
p
)
ω
u
,
p
\text{GAUC}=\frac{\sum_{(u,p)} \omega_{(u,p)} \times \text{AUC}_{(u,p)}}{\sum_{(u,p)}\omega_{u,p}}
GAUC=∑(u,p)ωu,p∑(u,p)ω(u,p)×AUC(u,p)
这里,权重
ω
u
,
p
\omega_{u,p}
ωu,p可以是每个用户view或者click的次数,而且会过滤掉单个用户全是正样本或负样本的情况。
2. GAUC一些理解
2.1 为什么在推荐中,GAUC要比AUC更适合
auc反映的是整体样本间的一个排序能力,而我们实际要衡量的是不同用户对不同广告之间的排序能力。
2.2 如何处理全是正样本 or 全是负样本的样本
计算GAUC的时候要过滤掉单个用户全是正样本或负样本的情况,原因有两个
- 消偏,提高置信度,其实对于全是负样本或者全为正样本的用户来说,那些数据都属于异常数据了,要么就只看不点,或者一直点的无效用户。
- 这两种情况的用户AUC没法计算,必须过滤掉,保证每个用户都有一个AUC值。
2.3 为什么对于广告而言,从某种意义上AUC比GAUC要更适用?
广告推荐不能混为一谈,对广告而言,模型对同一个广告不同用户的排序能力才是更重要的,广告服务的是广告主而不是用户,广告主的体验才是决定收入的关键
3. AUC一些理解
3.1 为什么order auc 比 click auc更大?
我们在实际业务中,常常会发现点击率模型的auc要低于购买转化率模型的auc。这是因为,AUC代表模型预估样本之间的排序关系,即正负样本之间预测的gap越大,auc越大。
3.2 click 还是order的线上线下差距更大?
order。这是因为,购买决策比点击决策过程长、成本重,且用户购买决策受很多场外因素影响,比如预算不够、在别的平台找到更便宜的了、知乎上看了评测觉得不好等等原因,这部分信息无法收集到,导致最终样本包含的信息缺少较大,模型的离线AUC与线上业务指标差异变大
3.3 为什么AUC对负采样不敏感?
由于AUC对分值本身不敏感,所有常见的正负样本采样,并不会导致AUC的变化。比如在点击预估中,处于计算资源的考虑,有时会对负样本做负采样,采样后并不影响正负样本的顺序分布。
即假设采样是随机的,采样完成后,给定一条正样本,模型预测为score1,由于采样随机,则大于score1的负样本和小于score1的负样本的比例不会发生变化。
但如果采样不是均匀的,比如采用word2vec的negative sample,其负样本更偏向于从热门样本中采样,会发现AUC值会发生剧烈变化。
3.4 对负样本负采样会导致其他评估指标如何变化?
对于准确率、召回率和F1值,
- 准确率: 负样本下采样相当于只将一部分真实的负例排除掉了,然而模型并不能准确地识别出这些负例,所以用下采样后的样本来评估会高估准确率;
- 召回率: 采样只对负样本采样,正样本都在,所以采样对召回率没什么影响。
- 两者结合起来,高估F1值.
3.5 一个python写的AUC的例子
def naive_auc(labels, preds):
M = sum(labels)
N = len(labels) - M
combine = [(pred, label) for pred, label in zip(preds, labels)]
sorted_pred = sorted(combine, key=lambda: x:x[0], reverse=False)
rank = 0
for index, tmp in enumerate(sorted_pred):
pred, label = tmp
if label == 1:
rank += index
return (rank-M*(M+1)/2) / (M*N)
if __name__ == '__main__':
labels = [0, 1, 0, 1]
preds = [0.1, 0.15, 0.2, 0.8]
print(naive_auc(labels, preds))

![【YOLOv8改进[Neck]】使用BiFPN助力V8更优秀](https://img-blog.csdnimg.cn/direct/7462a827f58b4462b2a2c1196c550107.png)